
📃 MySQL基础语法
1 | # 查看数据库 |
[!info]
Java英文字母区分大小写,MySQL英文字母是不区分大小写的。
1. DDL数据定义语言
用来定义数据库中的对象(database table)
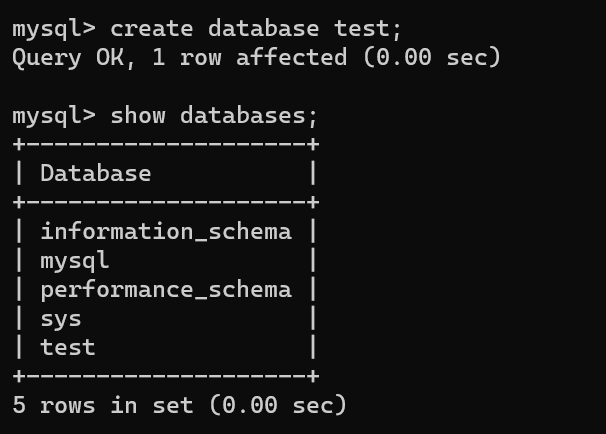
1.1 创建数据库
1 | create database 数据库名; |
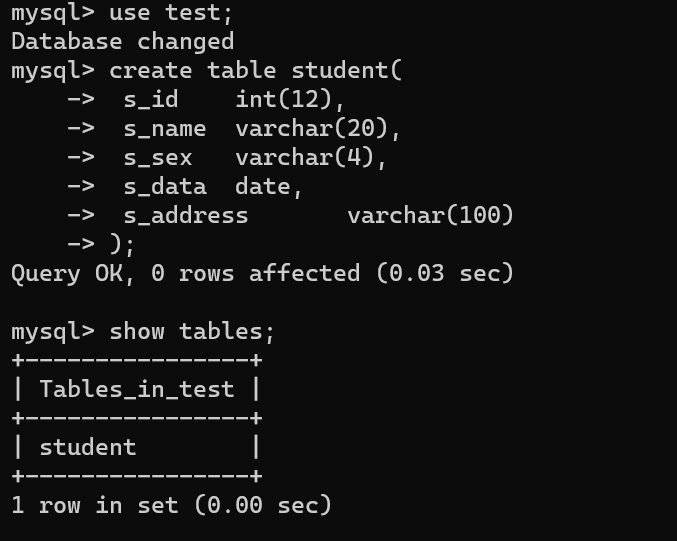
1.2 创建表格
1 | create table 表格名称( |
1.3 数据库中的数据类型
| 类型 | |||||
|---|---|---|---|---|---|
| 整数型 | tinyint | smallint | mediumint | int | bigint |
| 小数型 | float | double | decimal | numeric | |
| 字符串 | char | varchar | binary(二进制) | varbinary(二进制) | blob(二进制大文本)/text(正常字符大文本) |
| 日期/时间 | date(日期) | time(时间) | datetime(日期时间) | timestamp(时间戳) |
[!float]
float类型: float(m,n) 总共可以存储m位数字,小数点之后又n位。m取值范围是1-65 n取值范围是0-30。 默认m是10 默认n是0
1.4 创建一个学生表格
- [?] 创建一个学生表格,用来记录学生信息(学号、姓名、性别)
1 | create table student( |
1.5 修改表格结构
1 | # 修改表名 |
1.6 删库、删表
1 | # 删表 |
2. DML数据操作语言
用来操作数据库表格中的数据信息
2.1 新增记录
1 | # 新增一条记录 |
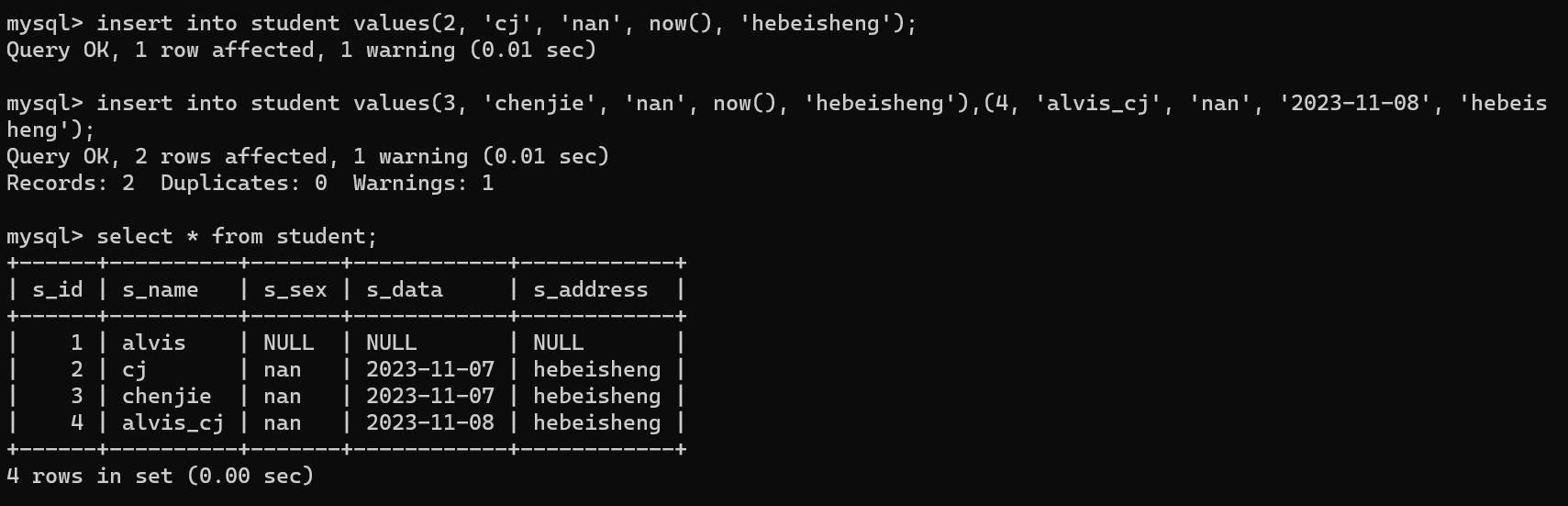
2.2 查询记录
1 | select 列名,列名,列名 from 表名; |
2.3 删除记录
1 | # 如果不加where条件,则删除所有数据 |
2.4 修改记录
1 | update 表名 set 列名 = 值, 列名 = 值 [where...]; |
2.5 小任务
- [?] 创建一张表格,用来记录员工信息,表格名称叫做EMP(Employee)
| empno(编号) | ename(姓名) | job(职务) | mgr(上级) | hiredate(入职日期) | sal(月薪) | comm(佣金) | deptno(部门) |
|---|---|---|---|---|---|---|---|
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800 | null | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600 | 300 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250 | 500 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250 | 1400 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500 | 0 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950 | NULL | 30 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300 | NULL | 10 |
1 | # 创建表格 |
3. DQL DML下分支
3.1 条件筛选 where
除了insert以外的其他三个语句都可以做筛选,where拼接在除了insert语句以外的其他语句基本结构之后。
1 | delete from 表 where ...; |
- 比较运算符
><>=<=!==
1 | # 查找语文成绩大于95分的 |
- 算数运算符
+-*/
1 | # 语文成绩加10分能优秀的 |
- 逻辑运算符
andornotand优先级高于or,or高于not
1 | # 语文和英语成绩都在95之上的 |
[!and]
and在sql底层的原理,先把文件读取出来,放到集合里面。然后循环集合筛选出语文成绩大于95分的。然后用筛选之后的数据进行循环,在找出英语成绩大于95分的。所以:为了提高效率,尽量将条件苛刻的写在前面。
4. [not] between and 在…之间的
1 | # 物理成绩小于等于八十五并且大于等于六十 |
[not] in满足其中一个条件就可以
1 | # 语文成绩等于78 或者 语文成绩等于87 |
[not] like模糊查询
%用来代替0-n个字符的。_用来代替1个字符(有且只有一个)
1 | # 查找c开头的 |
3.2 排序
order by排序,升序排序asc(默认) , 降序排序desc
1 | # 语文成绩按照降序排序 |
1 | # 联合排序 如果第一个条件一样,可以增加第二个条件 |
3.3 小任务
- [?] 创建一个person表,共有4列,并向表中插入数据:
| username | address | salary | department |
|---|---|---|---|
| 张三 | 武当 | 6000 | 保洁部 |
| 张无忌 | 魔教 | 6000 | 事业部 |
| 张三丰 | 武当 | 4000 | 产业部 |
| 周芷若 | 峨眉 | 8000 | 事业部 |
| 谢逊 | 魔教 | 5000 | 产业部 |
| 杨逍 | 魔教 | 7000 | 事业部 |
- 假设person表中所有人每个月还有100元奖金,查询出所有人的姓名,地址,年薪。
- 假设person表中所有人每年有1000元奖金,查询出所有人的姓名,地址,年薪。
- 请以下面的方式查询出所有信息:
| 姓名 | 居住地 | 月薪 | 年薪 |
|---|---|---|---|
| 张三 | 武当 | 6000 | 7200 |
- 查询出所有部门为事业部的所有人信息。
- 查询出所有地址为魔教的所有人信息。
- 查询出所有工资为6000元的人的所有信息。
- 查询出所有工资在6000-8000之间的所有人的信息。
- 查询出所有工资是6000,7000,8000的所有人的信息。
- 查询出所有工资在6000-8000之间,或者姓张的所有人的信息。
- 查询出所有工资为6000,7000,8000,或者姓张,并且不叫张三丰的所有人的基本信息。
- 查询出所有工资为5000,或者叫张三的人的所有信息。
- 查询出所有魔教人的信息,按照人名升序排序。
- 查询出所有工资高于5000的人员信息,按照address降序排序。
- 查询出所有人的信息,先按照salary降序排序,后按照人名升序排序。
1 | # 创建表格 |
3.4 函数
- [?] 函数可以放置在什么位置上?
1 | # 查询中用来显示的部分 |
- 比较函数
1 | isnull(值); 是空值返回1 不是空值返回0 |
- 数学函数(数值函数)
1 | abs(); 绝对值 |
- 日期和时间
1 | now(); 当前时间 |
- 控制流程函数(转换函数)
1 | if(条件,a,b); |
- 字符串函数
| sql | String |
|---|---|
| length() | length() |
| concat() | concat() |
| substr() | substring() |
| instr() | indexOf() |
| replace() | replace() |
| upper() | toUpperCase() |
| lower() | toLowerCase() |
| ltrim()/rtrim() | trim() |
| lpad()/rpad() | |
| reverse() |
1 | # length |
- 分组函数(聚合函数)
distanct 列,列可以去掉重复元素。用法类似于order by
1 | # 他会先去查stdent文件,最后会展示出很多相同的时间 |
分组函数+分组条件
分组函数:
count()
max() min() avg() sum()
分组条件:
如果sql语句中一旦搭配了分组条件,能展示得信息只有两种: 分组条件、分组函数
group by 列 having与where一样,但是他的优先级低于group by where是高于group by
1 | # 1.查询student表格中每一个班级有多少同学 |
嵌套
在一个完整得sql语句中,嵌套了另一个完整得sql语句
1 | # 查询student表格中语文成绩最高得人 |
1 | # 查询在深圳班级上课得同学有哪些 |
3.5 小任务
| 员工编号 | 姓名 | 部门 | 生日 | 工资 | 职务 | 信息更新时间 |
|---|---|---|---|---|---|---|
| 1 | 赵一一 | C | ‘1980-10-11’ | 10000 | 程序员 | 系统当前时间 |
| 2 | 钱二二 | C | ‘1981-10-12’ | 20000 | 程序员 | 系统当前时间 |
| 3 | 孙三三 | C | ‘1982-9-1’ | 30000 | 项目经理 | 系统当前时间 |
| 4 | 李四四 | JAVA | ‘1983-9-2’ | 40000 | 程序员 | 系统当前时间 |
| 5 | 周五五 | JAVA | ‘1984-11-1’ | 50000 | 程序员 | 系统当前时间 |
| 6 | 吴六六 | JAVA | ‘1985-1-1’ | 70000 | 项目经理 | 系统当前时间 |
| 7 | 郑七七 | JAVA | ‘1986-11-2’ | 50000 | 程序员 | 系统当前时间 |
- 请建立User表保存员工的相关信息,生日,信息更新时间用date类型。
- 查询每个部门最高工资,最低工资,平均工资。
- 给所有项目经理工资涨10000。
- 给工资低于30000的员工工资涨到30000。
- 查询各部门的工资总额,平均工资,最高工资,最低工资。
- C部门的项目经理离职,删除其信息。
- C部门的程序员全部转入JAVA部门,更改信息。
- 查询11月过生日的员工。
- 查询本月过生日的员工。设计一个通用的语句,不要用11月判断。
- 查询整合部门后表中记录的所有记录,按照薪资从高到低排布。
1 | # 1. |
3.6 终极任务
- [?] DEPT部门表
| deptno | dname | loc |
|---|---|---|
| 10 | ‘ACCOUNTING’ | ‘NEW YORK’ |
| 20 | ‘RESEARCH’ | ‘DALLAS’ |
| 30 | ‘SALES’ | ‘CHICAGO’ |
| 40 | ‘OPERATIONS’ | ‘BOSTON’ |
- [?] 条件筛选练习(EMP表)
- 查询部门30中得雇员
- 查询所有办事员(CLERK)得姓名、编号、部门
- 查询佣金(comm)高于薪资(sal)得雇员
- 查询那些人没有佣金(comm)
- 查询佣金(comm)高于薪金(sal)60%的雇员
- 显示所有人的姓名,月薪,年薪
- 找出部门10中所有经理和部门20中的所有办事员的详细资料
- 找出部门10中所有经理、部门20中所有办事员,既不是经理又不是办事员,但其薪金>=2000的所有雇员的资料
- 找出不收取佣金或收取的佣金低于500的雇员
1 | # 1. |
- [?] 排序练习(EMP表)
- 查询所有人员信息,按照工资升序排列
- 查询所有人员姓名,工资,佣金,按照工资降序排列,若工资相同则按照佣金升序排列
- 查询工资大于两千的所有员工,按照工资降序排列
- 查询所有人的信息,按照姓名排序
- 查询工资在2000-3000之间的员工信息,按照雇佣日期升序排列
1 | # 10. |
- [?] 函数练习(EMP表)
- 显示正好为6个字符的雇员姓名
- 显示所有雇员的姓名的前三个字符
- 显示所有雇员的姓名,用a替换所有A
- 显示不带有R的雇员姓名
- 显示只有首字母大写的所有雇员的姓名(MySQL不区分)
- 找出早于35年之前受雇的雇员
- 显示出所有雇员的姓名以及满10年服务年限的日期
1 |
|
- [?] 分组函数练习(EMP表)
- 显示每种工作的人数
- 显示工作人数大于3的工作的平均工资
- 显示出经理有几种不同的工资
- 显示出30号部门有几种不同的工作
- 显示出emp表数据中不同月份受雇用的人数
- 显示出每个管理者手下带了多少个员工
- 显示出收取佣金的雇员的不同工作
1 | # 22. |
- [?] 嵌套查询练习(EMP表)
- 查询平均工资大于900的部门中的所有员工
- 查询工资比ALLEN多的所有员工
- 查询薪金高于工资平均薪金的所有员工姓名,部门编号,具体薪资
- 列出与scott从事相同工作的所有员工信息
- 查询薪金大于部门30中的员工最高薪金的所有员工的姓名,薪金和部门编号
- 查询在部门sales工作的员工的姓名
1 | # 29. |
3.7 关键字使用 in any some all
in : 满足查询子集的某一个即可 (=),in后面的括号内可以是常量固定值,也可以是sql语句查询出来的结果。
1 | select * from student where loc in (1, 2); |
下面三个关键字后面不允许写固定值,只能写sql语句
any : 满足查询子集中的某一个即可(> <)
1 | # select classid from myclass where classid > 2 结果 3,4 |
some : 与any完全一致
1 | select * from student where classid >some(select classid from myclass where classid > 2); |
all : 满足查询子集的全部才可以
1 | select * from student where classid >all(select classid form myclass where classid < 2); |
3.8 集合操作-并集union
将两个表的数据合并成一个表
1 | select s_id, s_name, s_sex from student union select classid, classname,class_address from myclass; |
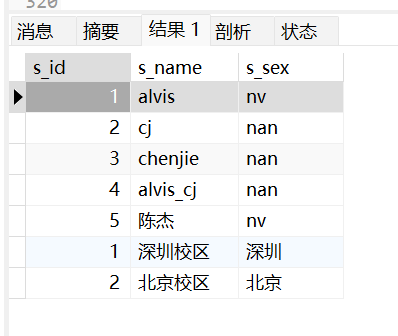
[!union]
注意: 查询的两个表的列数必须是一致的,每一列的类型是否相同是没有要求的。
[!union和union all区别]
注意:union会把两条重复的数据做处理,只保留一条(性能慢,记录的是第一次出现的记录);而union all不做任何处理,两条重复的数据全部保留。
3.9 列的约束[[#1. DDL数据定义语言]]
- 主键约束
每一个表格内,只能有一个列被设置为主键约束,主键约束通常是用来标记表格中数据的唯一存在。
要求: 要求当前列不能为null值,值是唯一的不能重复
1 | # 标准写法 |
- 唯一约束
可以为表格中的某一列添加唯一约束,约束与主键类似。唯一约束表示的是列的值不能重复,但是可以为空。唯一约束在表格中可以存在多个列
1 | # 标准写法 |
- 非空约束
在表格的某一个列上添加非空约束,当前列的值不能为null
1 | alter table 表名 modify 原列名 原列类型 not null; |
- 外键约束
约束自己表格内的信息不能随意填写,受到另外一个表格某一列的影响。表格内的信息,得是另一个表格得列。另一张表的列是唯一约束(主键,唯一)
表格中可以有多个列被设置为外键约束。
1 | alter table 表名称 add constraint fk_当前表_关联表 foreign key(列) references 另一个表(列); |
- 检查约束
小任务
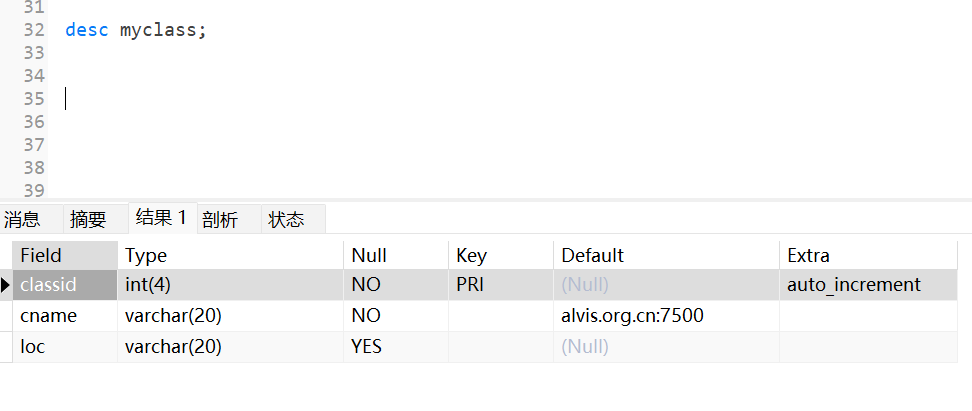
- [?] 设计一张表格myclass, 用来记录班级的信息
classid:班级编号 --> 主键cname: 班级名称 --> 非空loc: 班级位置城市 --> 唯一- 删除三个约束,将表格还原成最原始的格式
1 | create table myclass( |

- [?] 设计一个存储学生信息的表格student
sid sname sage ssex classid
1 | create table student( |
3.10 联合查询
- 广义笛卡尔积:
1 | # 将两张表或者多张表拼接成一张表,列相加,行是相乘的关系 |
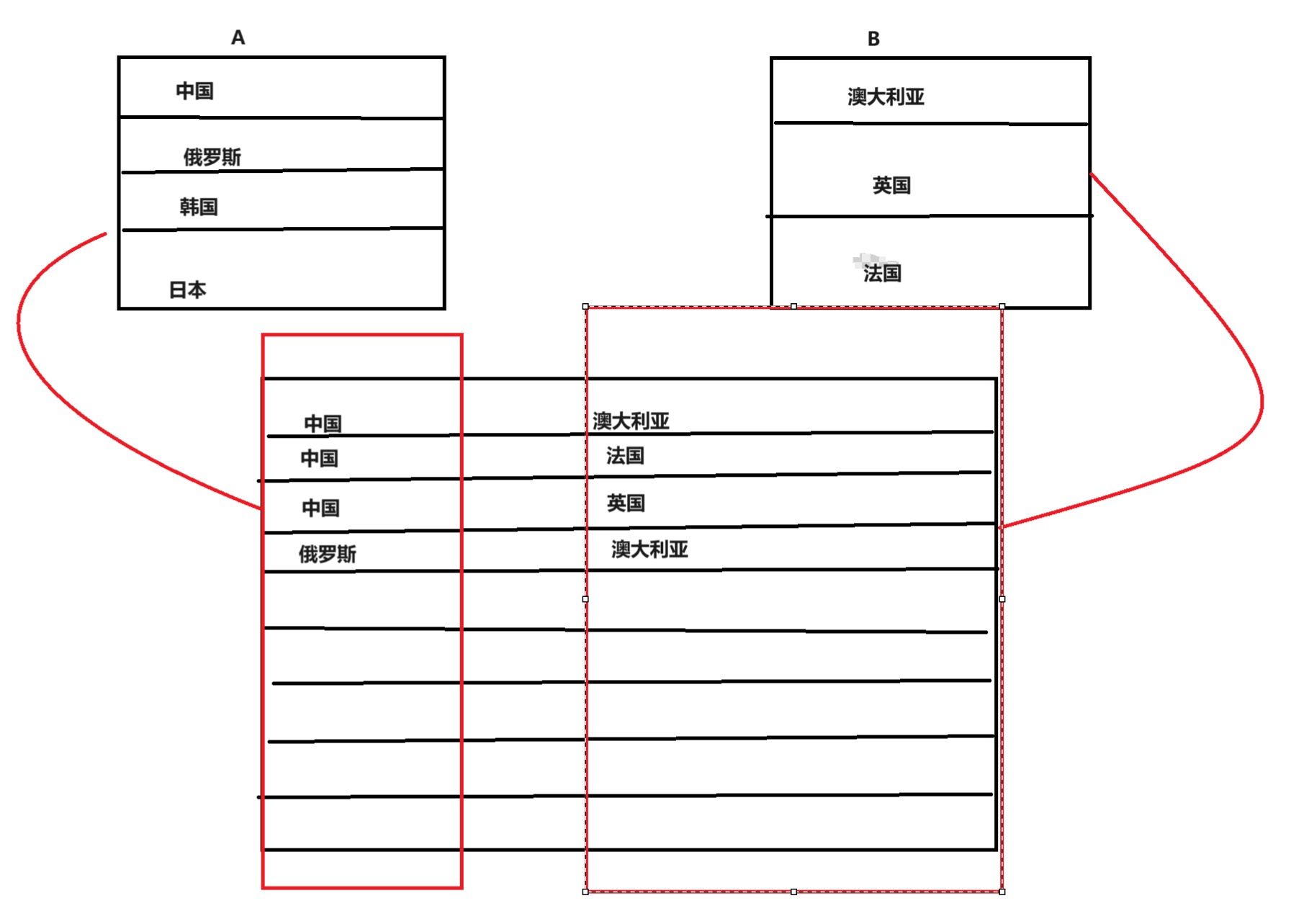
- 外连接
1 | # A表格先出现,A的列就在左边展示。反之则展示B表格的列在做左边 |
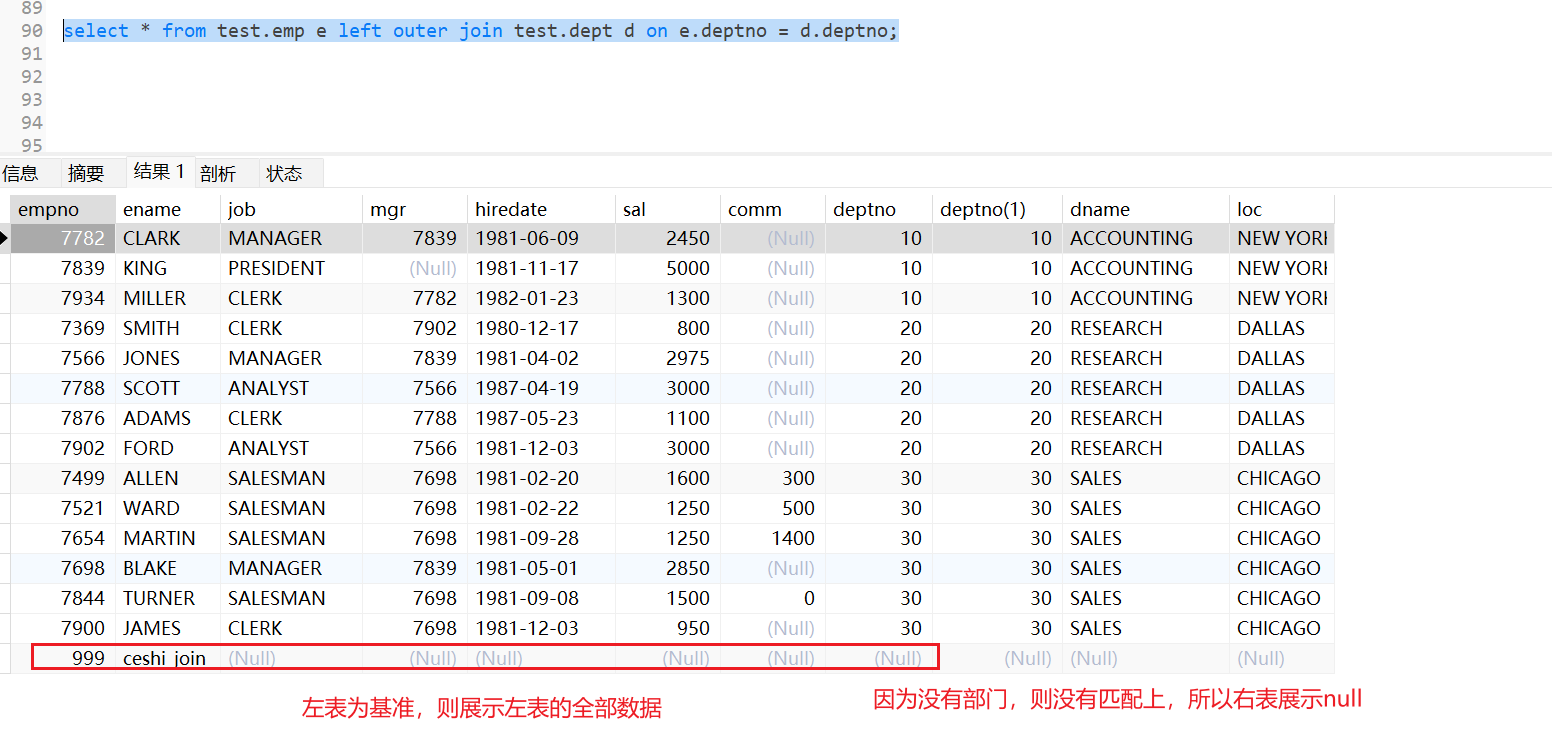
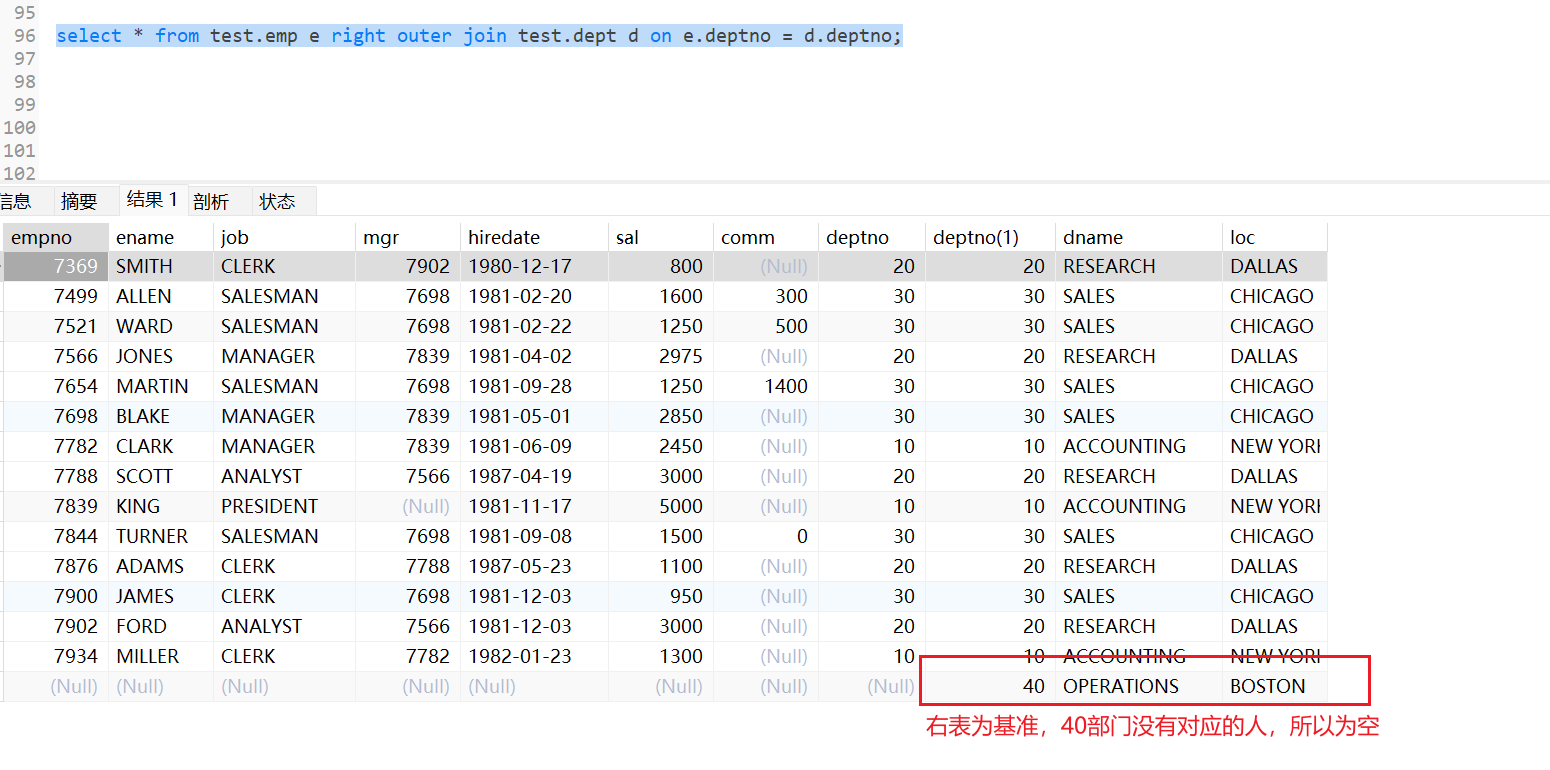
1 | select * from test.emp e right outer join test.dept d on e.deptno = d.deptno; |
- 内连接(自连接)
1 | # 内连接和笛卡尔积连接一样,但是性能比笛卡尔积连接性能更高 |
3.11 联合查询练习
- [?] 设计表关系如下:
国家表(Country)
| 国家cid(主键) | 国家名称(cname) |
|---|---|
| 1 | 中国 |
| 2 | 美国 |
| 3 | 日本 |
地区表(Area)
| 地区aid(主键) | 地区名称aname | 国家cid(外键) |
|---|---|---|
| 1 | 北方 | 1 |
| 2 | 南方 | 1 |
| 3 | 西部 | 2 |
| 4 | 东部 | 2 |
| 5 | 北海道 | 3 |
| 6 | 四国 | 3 |
城市表(city)
| 城市cityid(主键) | 城市名称(cityname) | 人口数量(citysize) | 地区(aid外键) |
|---|---|---|---|
| 1 | 哈尔滨 | 750 | 1 |
| 2 | 大连 | 50 | 1 |
| 3 | 北京 | 2000 | 1 |
| 4 | 上海 | 1500 | 2 |
| 5 | 杭州 | 800 | 2 |
| 6 | 洛杉矶 | 1200 | 3 |
| 7 | 休斯顿 | 750 | 3 |
| 8 | 纽约 | 1000 | 4 |
| 9 | 底特律 | 500 | 4 |
| 10 | 东京 | 1500 | 6 |
| 11 | 名古屋 | 50 | 5 |
| 12 | 大版 | 20 | 6 |
- 查询人口数在1000到2000之间得城市所属在那个地区
- 查询每个国家得城市个数,按照城市个数升序排序
- 查询各地区城市人口平均数,按照人口平均数降序排列
- 查询哈尔滨所在国家得名字
- 查询各个地区名字和人口总数
- 查询美国有哪些城市 列出城市名
- 查询人口最多得城市在那个国家
- 查询每个国家得人口总数
- 查询城市人口总数为1500得国家名字
- 查询个地区总人数 按照人口数总量降序排序
- 查询人口总数超过5000得国家名称
- 查询人口数大于杭州的城市有哪些
1 | create table country( |
3.12 行列互换+分页查询
行列互换示意图:
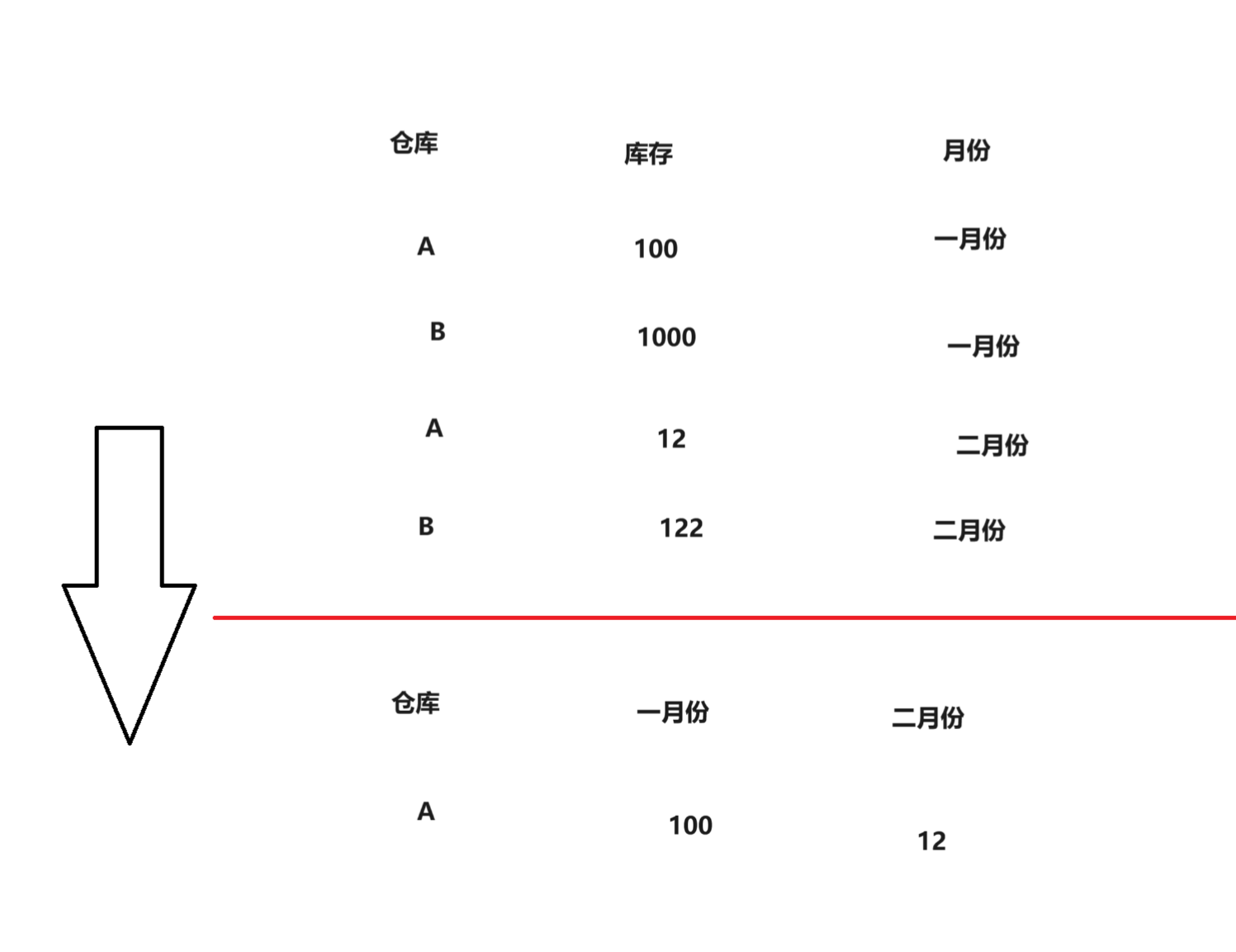
1 |
|
分页查询 limit
1 | select * from emp; order by sal desc; |
4. DCL数据控制语言
用来控制数据库中用户的权限
4.1 配置mysql全局环境变量
- 找到mysql的位置(复制路径)
C:\Program Files\MySQL\MySQL Server 5.7\bin
- 配置环境变量(找到path路径,然后将复制的mysql路径添加进去)
4.2 mysql创建用户
-
root账号可以查看mysql数据库中的user表格。里面记录着所有用户信息
user 列host 列password 列authentication_string 列 -
先创建一个新的用户
[!info]
新创建的用户只有一个默认的权限,Usage只允许登录,不允许做其他事情
1 | create user '用户名'@'IP' identified by '密码'; |
4.3 给新用户赋予权限
1 | grant 权限 on 数据库名.表 '用户名'@'IP'; |
4.4 回收用户权限
1 | revoke 权限 on 数据库。表名 from '用户名'@'IP'; |
4.5 修改用户密码
1 | update user表 set authentication_string = password('123456'); |
5. TPL事务处理语言
可以理解为多线程并发操作同一个文件
事务的四大特性(ACID)
A:Atomicity --> 原子性
一个事务中的所有操作是一个整体,不可再分割。事务中的所有操作要么成功,要么都失败。
B:Consistency --> 一致性
一个用户操作了数据,提交以后另一个用户看到的数据与之前用户看到的数据效果是一致的。
I:Isolation --> 隔离性 --> 事务隔离级别
指的是多个用户并发访问数据库时,一个用户操作数据库,另一个用户不能有所干扰,多个用户之间的数据事务操作要互相隔离。
D:Durability --> 持久性
指的是一个用户操作数据的事务一旦被提交(缓存–>文件)他对数据库底层真实的改变是永久性的,不可返回。
-
开启一个事务
- 每一次执行的一条sql语句之前mysql数据库都会默认开启
- 事务中的所有操作要么都成功,要么都失败
- begin手动开启事务
- start transaction;和beigin一样
-
执行操作
- insert update delete
- select
- 可能不止一条语句
-
事务的处理
- 提交/回滚/保存还原点
- mysql数据库会默认执行提交事务
[!info]
mysql数据库事务管理默认的效果是可以更改的
- [>] 更改mysql数据库事务管理状态
1 | # 自动提交事务变量 |
1 | # 创建表格 |
1 | # 事务的原子性 |
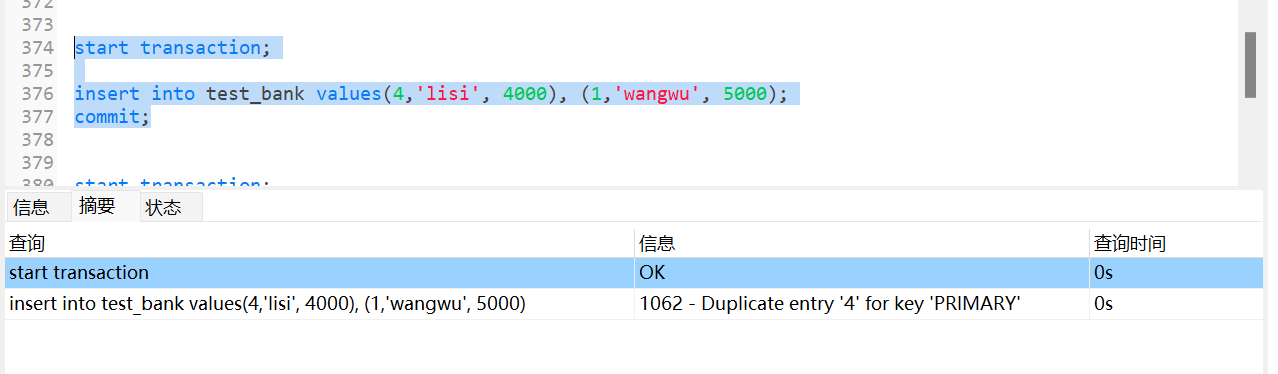
1 | # 事务的一致性 |
事务隔离级别
| 级别 | 解释 |
|---|---|
| Serializable | 最高,可以避免所有问题,性能慢 |
| Repeatable Read | 可重复读(mysql默认管理级别) |
| Read Committed | 读已提交 |
| Read UnCommitted | 读取未提交 |
级别低的会产生问题
- 脏读
- 一个人读到了另外一个人还没有提交的数据
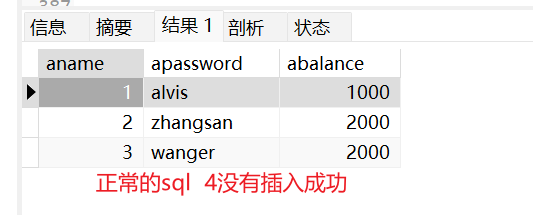
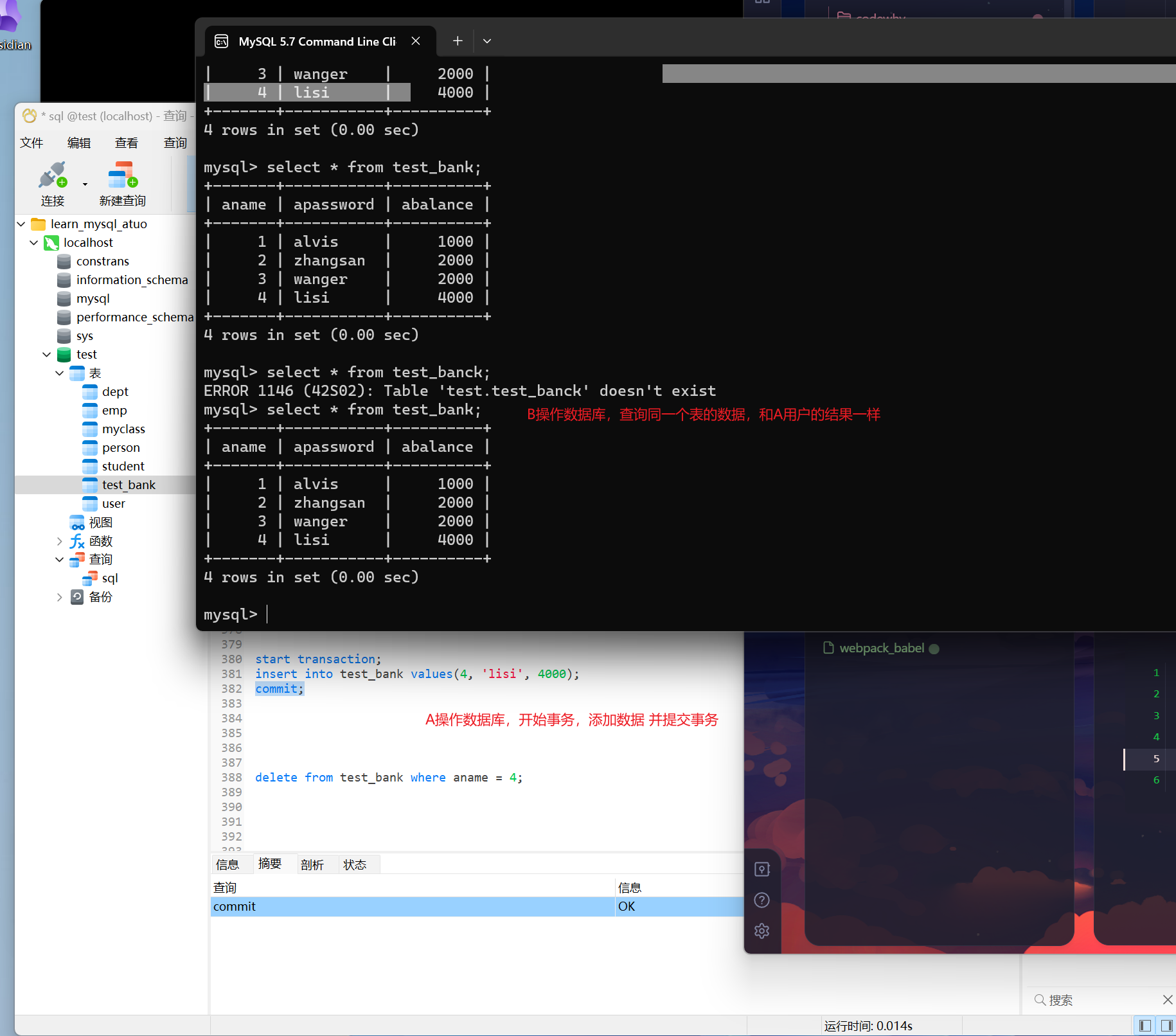
- [!] A B在操作同一张表,A修改了数据没有提交,B读取到了。A不提交了,回滚回来。B读取到的数据就是无用数据
- 不可重复读
- [!] A B在操作同一张表格,A先读取了一些数据,读完之后B在此时将数据做了修改/删除。A在按照之前的条件重新读一遍,与第一次读取的不一致
- 幻读(虚读)
- [!] A B 操作同一个表格,A先读取了一些数据,读完之后B在此时将数据做了新增,A在按照之前的条件重新读一遍,与第一次读取的不一致
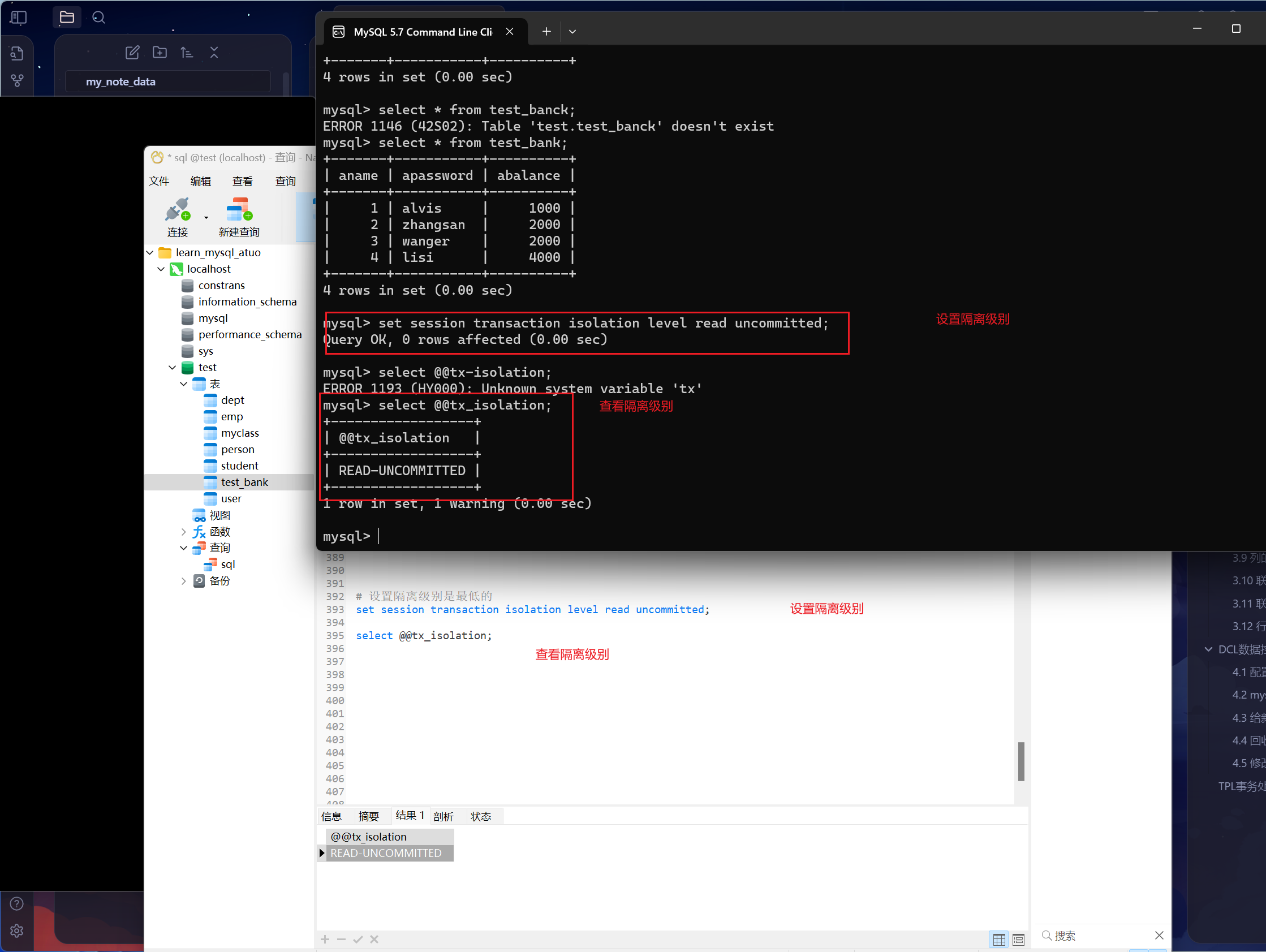
修改隔离级别
1 | set session transaction isolation level xxx; |
1 | set session transaction isolation level read uncommited; |
1 | # 脏读 |
read committed解决脏读
1 | A、B:都设置隔离等级 |
1 | # 不可重复读 |
repeatable read解决不可重复读
1 | set session transaction isolation level repeatable read; |